Optimizing a Site
You can take actions to optimize the site where your output is published. This includes generating a sitemap, including a robots.txt file, enabling non-XHTML files in search, showing links, changing search pagination, and adding search abstracts.
[Menu Proxy — Headings — Online — Depth3 ]
Generating Sitemaps
For web-based targets, you can generate a sitemap when compiling your output. This helps with search engine optimization (SEO), making it easier for search indexing services (i.e., spiders, crawlers, or bots) to find your output. Therefore, the entire output is indexed and search engine results are improved.
How to Generate a Sitemap
- Open a web-based target.
- On the Search tab of the Target Editor, select Generate Sitemap.
-
In the Web URL field enter the path where the output is ultimately published.
Example https://help.madcapsoftware.com/flare2024 r2/
Note Be sure to include the full path—including "https://"—when entering the web URL.
- Click
") to save your work.
to save your work.
Including a Robots.txt File
A robots.txt file is typically implemented by a website developer or website owners. It is used to advise search engine robots and spiders about what site content can and cannot be crawled. The robots.txt protocol is a simple text file that you can create in a text editor.
There are several reasons why you may want to consider creating a robots.txt file to use with your published output:
-
Block Access to Content If you do not want the robot or spider to crawl certain content, you may want to publish those content files in a password-protected directory and include a robots.txt file. It is recommended that you work with your website or web server administrator to ensure your requirements are met.
- Block Access to Specific Files and/or Folders If you have specific content that want to block from search engines, you can advise cooperating robots and spiders to exclude that content from their index. Keep in mind that most major search engines cooperate with these instructions. However, some search engines do not.
- Block Your Site from Specific Search Engines If you would like to block a specific search engine from crawling your site, you can advise its robot or spider to exclude your site from its index. To be successful, the robots.txt file must explicitly define the robot to block by name and the spider must be programmed to cooperate with your instructions.
How to Include a Robots.txt File
- Open a text editor.
- Create a new file and name it "robots.txt."
-
Include the desired instructions.
Tip To learn what to include in a robots.txt file, see http://www.robotstxt.org/. You should discuss specific requirements with your web server administrator and/or website developer.
-
Place the file at the root of the website hosting your published content.
Example You plan to publish your Help content to a site named:
https://www.help.example.com
In this scenario, you should place the robots.txt file at the root of the site:
https://www.help.example.com/robots.txt
- Publish your content and ensure the robots.txt file is still in place.
-
Test your robots.txt using a validation tool. Some major search engines provide their own testing tools (e.g., Google) .
Note Most major search engines (e.g., Google, Bing, and Yahoo) are known to cooperate with the instructions in a robot.txt file. However, many search engines also have the ability to discover information using other methods. For example, let's say you have blocked a file named "form_1.html" in robots.txt. However, another website has created a link on their site to your "form_1.html" page. In this scenario, the URL for that linked page may be included in an engine's search results.
Note It is also generally understood that there are existing search engines, including malicious ones, that do not cooperate with the robots.txt protocol. Be sure to work closely with a web developer or your web host to ensure you get the best results possible with your robots.txt file.
Enabling Non-XHTML Files in Search
Because search engines have added non-HTML formats to their search indexes, it is helpful to enable non-XHTML search in your output. This allows the Flare search engine to return matches for non-HTML content in your project (e.g., PDF, DOC, and XLS files). You can enable non-XHTML search in the HTML5 and WebHelp Plus server-based outputs.
Showing Links
You can add a link to the top or bottom of topics in HTML5, WebHelp, or WebHelp Plus outputs. This link will not display unless the output topic is opened as a standalone (outside of the main navigation framework of the output). By clicking the link, a user can view the standalone topic in the main navigation framework.
See Showing Links in Standalone Topics.
Changing the Number of Search Results Per Page
You can change the number of search results that appear on each page in HTML5 outputs. This makes it easier for users to navigate between pages of search results and improves search result loading times, especially for users who access your output from a mobile device. In order to use this feature, you must be using Elasticsearch or MadCap Search. This is feature is not suppoted for Google Search. See Setting Up a Search Engine.
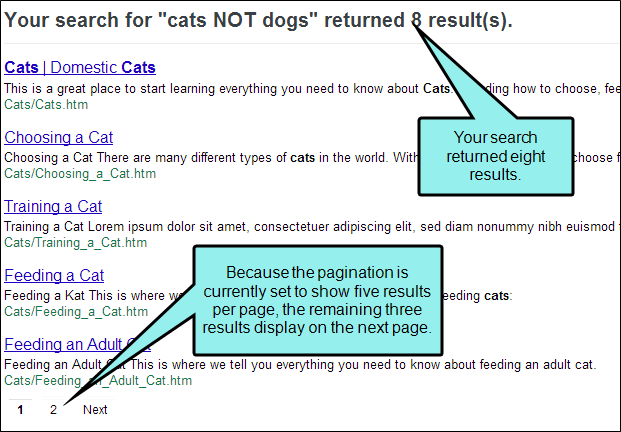
See Setting the Number of Search Results Per Page.
Changing the Abstract Character Limit in Search Results
In HTML5 output, you can set a character limit for automatically generated abstracts that appear in your search results. This allows your users to see a brief summary of each topic in the search results, while keeping the search results page easy to scan. You can set the character limit as long or as short as you like. When creating an automatic abstract, Flare scans all text elements in the topic, including headings and paragraphs, and includes them in the abstract until the character limit is met. This feature is only supported for MadCap Search.


You can also add a manual search abstract using meta descriptions in the topic's Properties dialog.

